
数据分析和挖掘在电商精细化运营中的应用
一、客户细分 — RFM 模型
客户细分比较经典的分析模型是RFM 模型,根据著名的“二八”原则,通常企业80% 的利润来自于20% 的重要客户,因此挑选出对企业最有价值的重点客户,发掘潜在的新客户,实施增量销售和交叉营销,保持客户对企业的忠诚度是电子商务分析的重要策略。RFM 模型的三个关键指标是客户的最近一次消费间隔(Regency)、消费频率(Frequency)以及消费金额(Monetary),并根据这三个变量对客户进行细分从而衡量买家对平台销售业绩的价值贡献。理论上来说,最近购买产品或者服务的顾客,购买频次更高的顾客,更有可能成为再次光顾的消费者,对企业的营销推广信息也更为敏感。最近一周才在该平台购买产品的顾客会比半年前甚至一年前消费过的顾客更有可能打开该平台的促销邮件;每个月都在平台购买产品的高频用户会比半年才购买一次的用户更关注平台的新品推荐信息;而消费金额越多,当然越是企业必须重视的高价值用户,必须保持对这些用户的联系,维护好客户关系。
客户细分在电子商务中的是常见的分析需求,我们可以利用IBM SPSS Statistics 的“直销—选择方法—了解我的联系人”功能,利用企业的客户数据和交易数据进行RFM 分析,也可以利用SPSS 的聚类分析功能进行分析,下面用SPSS 的聚类分析方法——K-Means 聚类来举例。
聚类分析能够将一批样本数据根据其诸多特征,按照在性质上的亲疏程度(各变量特征上的总体差异程度)在没有先验知识(没有事先制定分类标准)的情况下进行自动分类,产生多个分类结果。现收集了某电子商务平台的部分买家数据进行分析,共4 个变量:客户ID,购买次数,交易总金额,最近一次购买时间间隔。应用SPSS 做聚类分析需要符合两个前提条件:1. 变量之间不存在较强的线性相关关系。
2. 变量值之间不存在数量级上的差异。因此,需要先对这些样本数据做相关性分析和描述性统计。
从描述性统计的运行结果交易总金额的均值为12487.17,标准差为24672.38 可以看出,数值之间的取值范围比较大,不能直接做聚类分析,需要对数据进行标准化处理并将标准化得分另存为变量。交易金额和交易次数之间的相关系数是0.481,存在弱相关性。可以使用SPSS 的K-Means 聚类功能对标准化后的变量进行分析。为了避免分组太多,对各个分组群的客户的理解不清晰,这里把聚类个数设置为3,运行聚类分析得出结果:
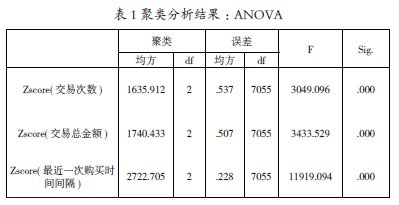
从运行结果表1 的数据来看, 按类别分组进行单因素分析,从F 值大小可以看出最近一次购买时间间隔(F 值为11919.094)对聚类结果贡献最大,其次是交易总金额,F 值大小为3433.529,同时各变量对聚类均有显著贡献,各个类别之间的差异是显著的。
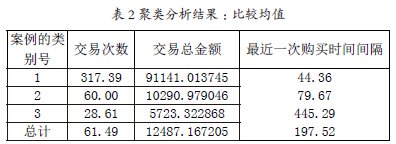
结合聚类分析结果的数据看,我们把买家分为3 类:第1 类买家人数最少,只有322 个,具有交易次数多,交易总金额高和最近一次购买时间间隔短的特性,这些买家应该是企业的VIP 级别买家,企业应该给予特殊的重视,设置专门的贵宾客服通道,优先解决这些买家纠纷投诉等问题,保持他们对网站的忠诚度;第二类买家人数为4430 个,交易次数和交易总金额相对较低,最近一次购买时间相对较远,是重要保持和发展买家,应该加强互动,通过新品,促销优惠活动信息通知等营销方法保持他们的活跃度,提高用户粘性;第三类买家人数2306 个,交易次数和交易总金额比较低,最近一次购买时间远,可能是即将流失或者已经流失的买家,要及时采取行动进行维护或唤醒,通过发送优惠券,问卷调查,客服跟进等方式了解买家流失原因有针对性地采取改进措施。
当然这个例子只是RFM 模型在精细营销中客户细分的一个简单应用,也有一些待改进的地方:客户细分只是考虑了交易次数,交易总金额和最近一次购买时间间隔三个变量,参考变量太少,且交易次数和交易总金额之间存在一定的多种共线性。在电商平台的运营分析中,可以增加用户登录,收藏,下单天数,评论等用户行为相关的变量来搭建更复杂的会员等级系统。
在运营过程中,针对不同主题的营销活动,对客户进行识别细分,再有针对地制定营销方案,必定会比盲目无针对性地发邮件或Push 给所有用户的转化效果好。如针对一个B2B 网站,要对某类批发类产品进行促销,可以定位之前买过相同或与其关联性较强的品类产品,且有批量购买历史等批发商用户行为属性的客户,把促销信息更精准地推广给这些客户群体,从而提高销售转化率。
对客户进一步细分也应用在分析用户留存和用户生命周期价值上,相关数据表明,开发一个新用户的成本是维护一个老用户成本的几倍,因此,在招募到新用户之后,企业更希望通过数据分析和挖掘来提升用户在生命周期中所带来的实际收入价值,确保营销策略获得最大的投资回报率。通过建立模型用聚类分析,关联规则等方法来分析用户流失特性,流失原因分析,根据用户生命周期规律把用户划分为不同阶段,对沉默用户和即将流失的用户及时进行干预,执行相应的唤醒和挽留策略,更精细化地运营,培养用户的忠诚度,让之为企业带来最大化的收入。
二、电商网站个性化推荐系统
随着互联网行业的发展,互联网用户所能获取的信息量激增,用户每天被海量的信息淹没,严重影响了获取所需信息的效率。对于千万级别产品量的电商平台来说,如果用户在浏览一段时间后没有找到自己想要的商品,就很可能失去耐心关闭网页。个性化推荐系统是精细化运营的一个产物,它给出了一个不错的解决方案。通过大数据分析用户的浏览日志和交易数据,通过关联规则和聚类等分析方法,计算购买了某些产品的买家或者具有相同或类似标签的用户会倾向购买哪些产品,从而更精准地向买家推荐产品。
目前,淘宝网和京东等各大电子商务平台也会根据买家信息偏好标签,买家搜索、收藏和加入购物车等用户浏览行为数据和购买交易数据两大维度扩展来进行判断,给买家进行个性化推荐,很多大型网站基本上实现了“千人千面”。
目前的推荐算法中,最为广泛采用的是基于协同过滤的推荐方法,主要有基于用户协同过滤和内容协同过滤两个大的方向:
1. 基于用户纬度的推荐,就是通过用户的购买和浏览行为多维度挖掘用户之间的相似度,形成与目标用户相似度较高的用户集合,再把这个集合中用户喜欢的而目标用户没有购买过的商品对目标用户进行推荐。
2. 基于内容的推荐,就是根据用户浏览或购买的服务和商品内容的相似度进行推荐。通过提取商品名称和描述的关键字,给商品打上各种标签:3C 电子产品类,家居用品类,运动户外类等等。粒度划分越细,推荐结果就越精确,从而利用关键字的相似度来做推荐。
举个例子,你最近想换一部华为手机,在网站上浏览了但是没有下单,在你下次登陆的时候,网站就会向你推荐你浏览过的手机相关的商品,这个是根据用户的浏览记录来进行推荐;当你下单以后,在加入购物车页面,网站又会向你自动推荐“购买了该商品的用户还购买了”,“您可能还需要”等一些关联商品。这些就是基于用户和基于内容维度的推荐。协同过滤的推荐算法的实现主要有收集用户偏好数据,找到相似用户和物品,计算推荐三个步骤。在当前大数据存储、数据挖掘和机器学习技术的高速发展下,推荐算法的应用越来越广泛,也越来越科学和智能。
总之,精细化运营的个性化推荐系统能够很好地解决信息过载问题,更高效地帮助买家找到自己想要的商品,改善用户体验,而对于商家来说,也可以让商家更精细地把流量投放给目标用户,从而提升营销的转化率和营销活动的投资回报率。
综上所述,在大数据时代,只有重视数据的价值,把数据分析和挖掘贯彻到日常的精细化运营中,才有可能在激烈的竞争中取胜。
参考文献:
[1] 周欢. 基于RFM 分析模式的零售业客户分群实现过程[J]. 金陵科技学院学报.2008.3.
[2] 林盛. 基于RFM 的电信客户市场细分方法[J]. 哈尔滨工业大学学报.2006.5.
[3]薛薇《. 统计分析与SPSS的应用》[M].中国人民大学出版社色.第二版.
[4] 李翠平. 大数据与推荐系统[J]. 大数据.2015.3.
[5] 王茜. 大数据环境下电子商务个性化推荐服务发展动向探析[J].商业研究.2014.08.
[6] 韩莉. 大数据时代的个性化推荐技术分析[J]. 晋中学院学报.2016.3.
[7] 孙耀.RFM 模型的改进及客户策略研究[J]. 现代经济信息.2010.22.
作者简介:
李海丽(1990—),女,广东罗定人,学历:研究生,工作单位:对外经济贸易大学,研究方向:大数据与互联网经济。
相关文章:
相关推荐:
网友评论: